
Büyük dil modelini (LLM — ChatGPT benzeri yapay zeka) bir özelliğe eklemek bir sprint işi gibi görünüyor; maliyeti kontrol altında tutmak ise en az bir çeyrek sürüyor. Deneme aşamasında (POC) her şey ucuz: az kullanıcı, kısa talimat metni (prompt), tek model. Trafik gelince fatura ve yanıt süresi (latency) birlikte büyüyor; o noktada "sonra bakarız" demek pahalıya patlıyor.
Üç katmanlı bir yaklaşım işe yarıyor. Birincisi prompt önbelleği: aynı sistem talimatı ve doküman parçaları (RAG — veritabanından çekilen metin parçaları) her istekte tekrar gönderilmesin. Redis veya uygulama içi önbellek yeterli. İkincisi model yönlendirme: "Bu yorum olumlu mu?" gibi basit sorular küçük modele, uzun analiz büyük modele gitsin. Kurallar sunumda değil, kodda olmalı. Üçüncüsü sert tavan: kullanıcı veya müşteri (tenant) başına günlük token limiti; aşımda servis çökmez, bilinçli şekilde kısıtlanır.
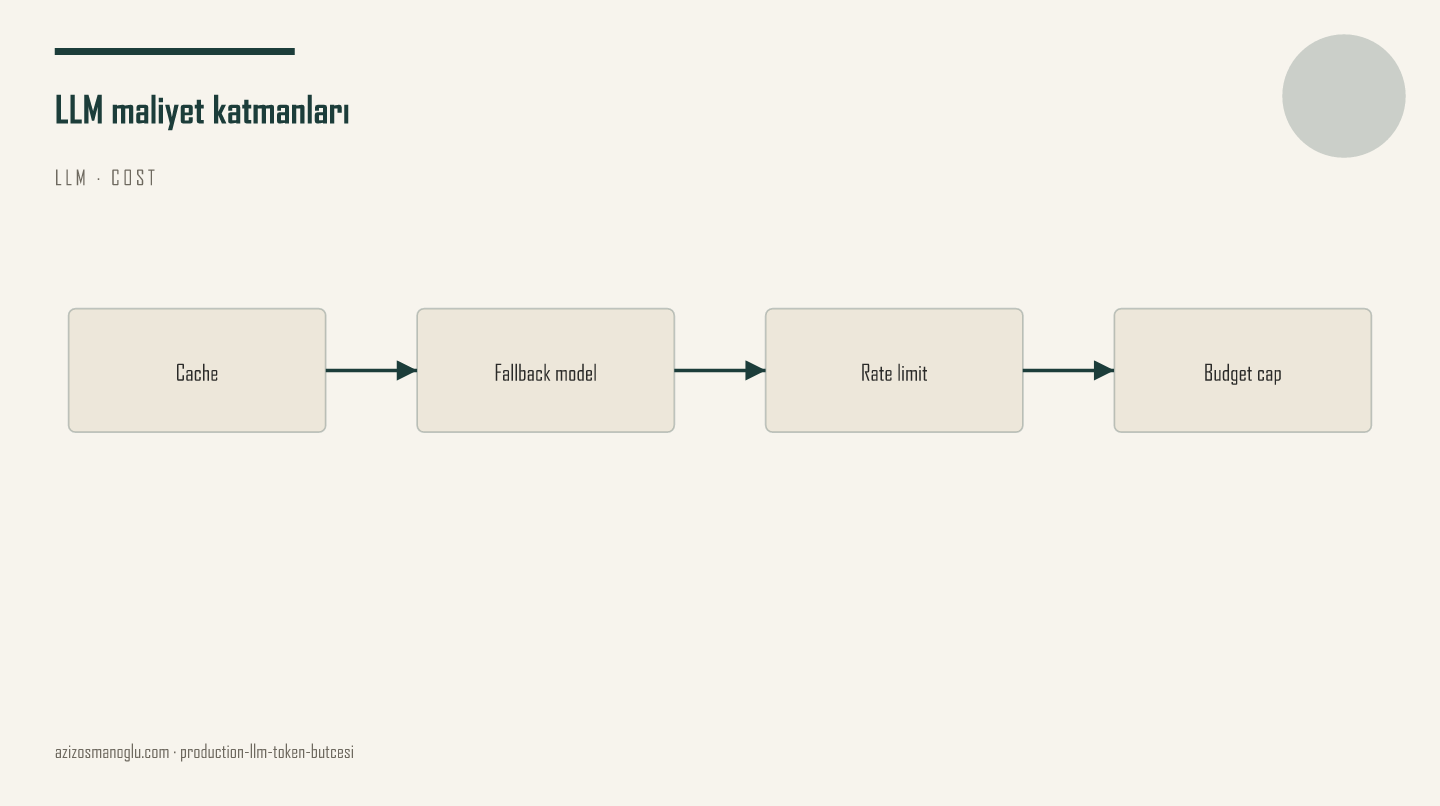 Ana model zaman aşımına uğradığında 503 hatası dönmek yerine önbellekteki veya yedek bir özet dönmeyi tercih ediyorum. Kullanıcı "şu an kısa özet modundayız" görür; sipariş ve ödeme gibi temel akışlar etkilenmez. Hız sınırında (rate limit) da aynı mantık: çıplak 429 hatası yerine anlaşılır bir mesaj.
Ana model zaman aşımına uğradığında 503 hatası dönmek yerine önbellekteki veya yedek bir özet dönmeyi tercih ediyorum. Kullanıcı "şu an kısa özet modundayız" görür; sipariş ve ödeme gibi temel akışlar etkilenmez. Hız sınırında (rate limit) da aynı mantık: çıplak 429 hatası yerine anlaşılır bir mesaj.
Canlı ortamda "model cevap vermedi" senaryosunu her şey yolunda gittiğindeki kadar tasarlamak gerekiyor. Maliyet alarmı geldiğinde özellik bayrağı (feature flag) ile LLM'i kapatıp operasyonu sürdürebilmelisin.
Özet: LLM maliyeti trafikle birlikte büyür. Önbellek, model seçimi ve günlük limit üçlüsü olmadan fatura sürpriz olur.